Introduction
词云是把一大篇文章里的词语摘出来,根据词语使用频率的高低,在图片里根据不同的大小来显示,非常直观,而且很浪漫。通过制作词云图,可以一目了然的发现你与TA之间的高频聊天词汇,比如“小可爱”(打扰了,我没有+_+),再加以Romantic Mask Photo渲染,会获得不错的效果噢。
目前已经有许多在线词云生成器,但一般只能试用、或有字数限制,且你自己也不放心自己的隐私传到互联网上。本文将主要介绍如何把你手机里的一条条聊天记录生成一张张美妙的词云图,主要分为以下两个部分:1、如何导出聊天记录?2、如何生成词云图。其实以上两个问题在Google、Baidu上都有很多教程,但是将其结合在一起的详细讲解却比较少,因此我才写一篇较为详细的介绍,主要以IOS为例。(PS:大家要遵纪守法、做一个好公民,微信聊天记录只许查看自己的呦~)
Method
如何导出聊天记录?
其实相对于Andriod来说,IOS可能会更加不好导出,我将主要介绍如何导出IOS的聊天记录。
事先准备
- 爱思助手(参看版本V7.98.22)
- 楼月导出工具(可在我的github下载)
原理
其原理主要是通过爱思助手将IOS的数据进行全备份,然后将软件数据导出,最后通过楼月助手解析加密的数据库,将聊天记录以HTML的形式导出
在爱思助手中对ipone进行备份
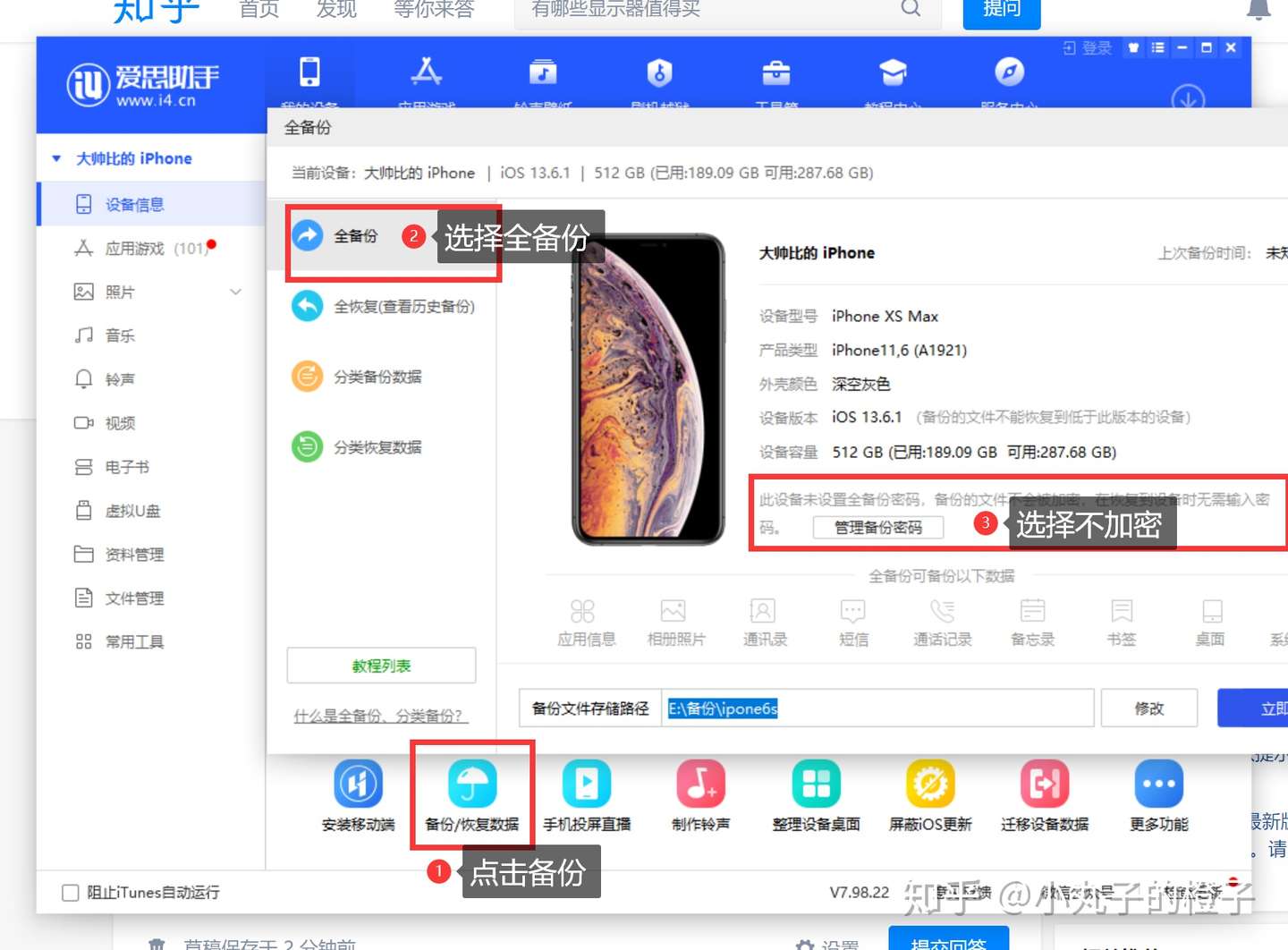
注意:这里的全备份并不是将你的所有数据都进行拷贝,可能使用空间40G,备份文件就4G,但时间可能得久一点,我的6s使用空间40G,备份时间大约20min。
查看备份
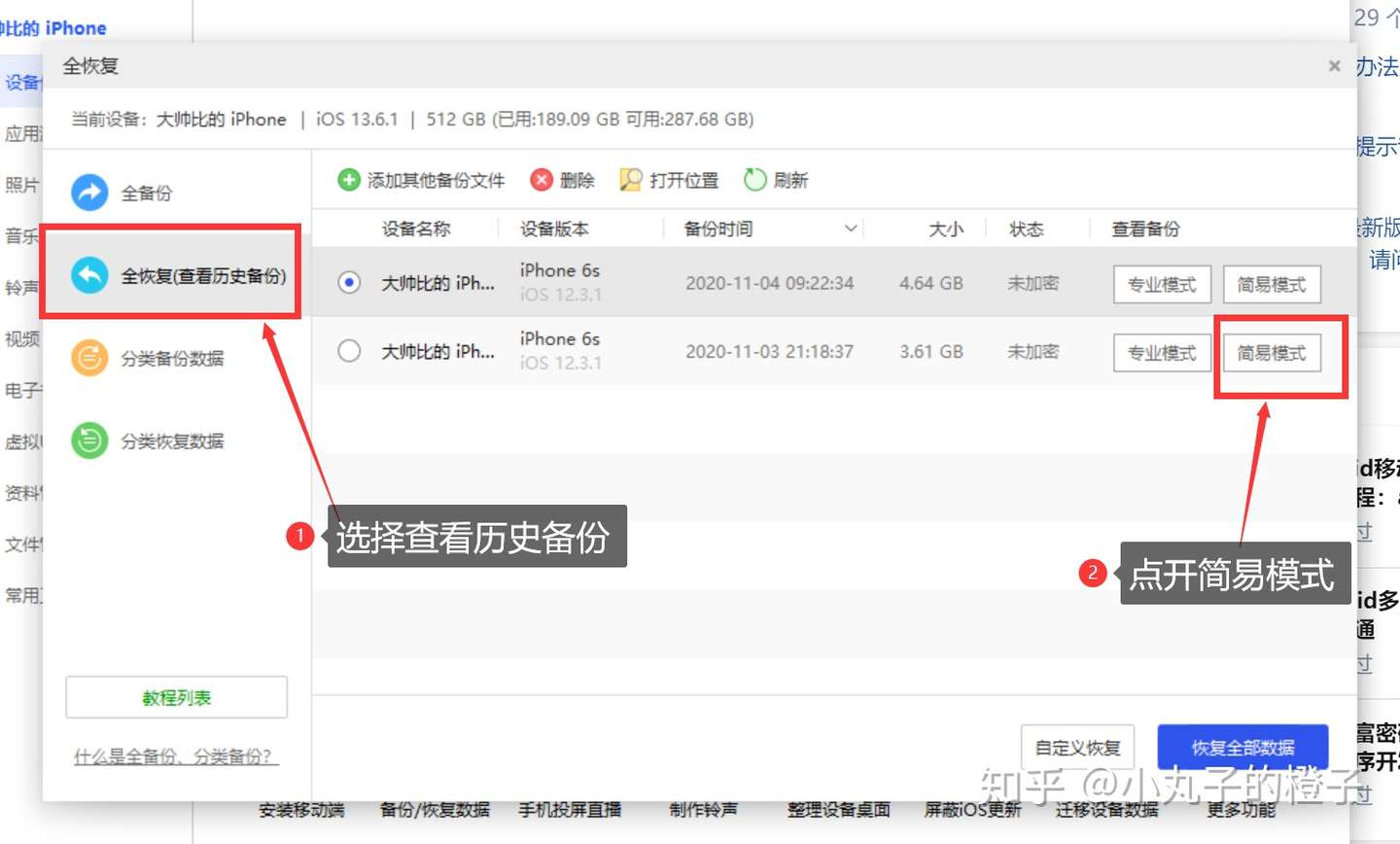
Tips:打开简易模式,可能会有点久,根据备份文件大小决定,我的大概耗时1-2min
在备份管理器中以简单模式查看并导出
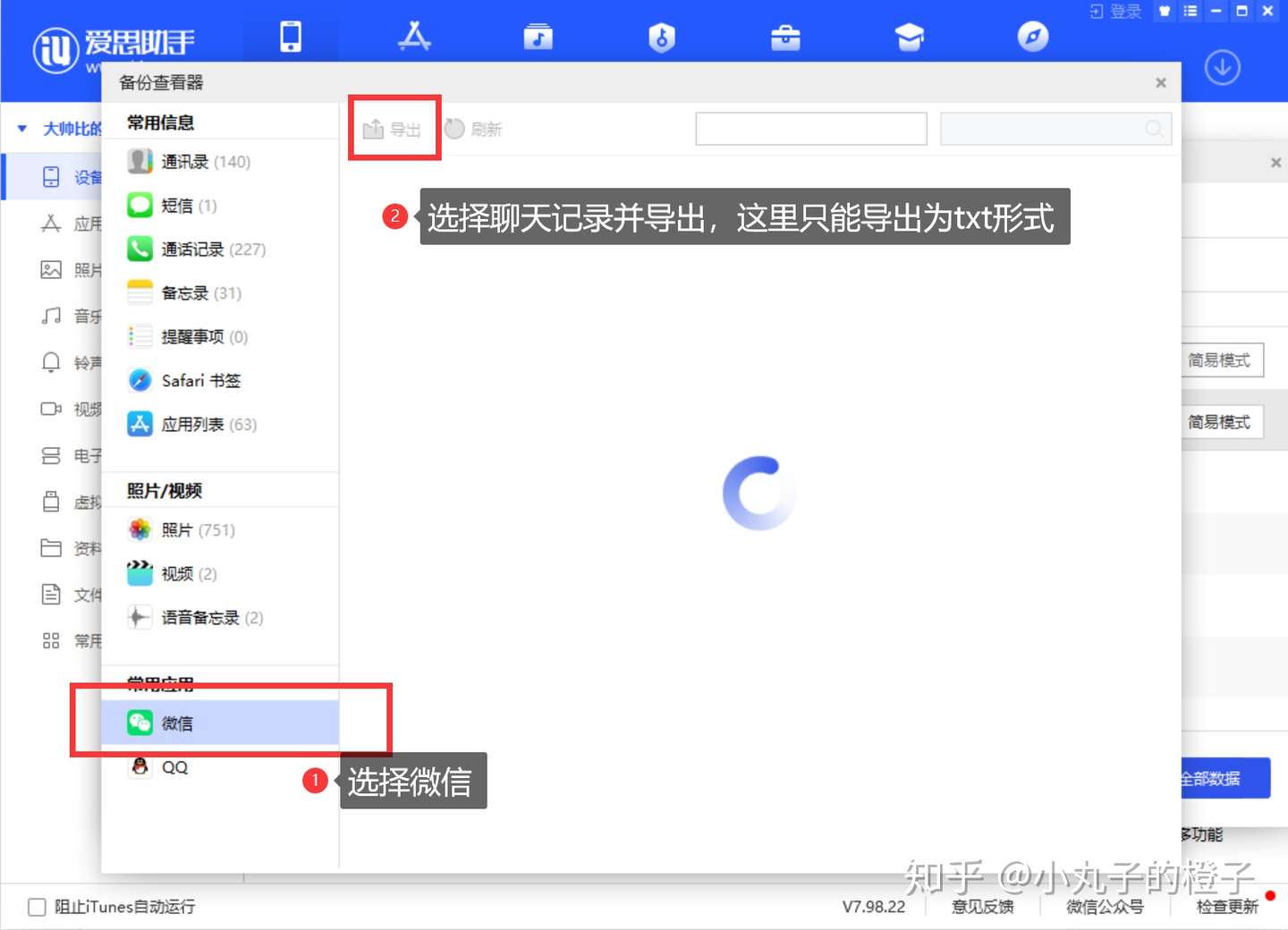
Tips:这里点击微信后可能加载的时间较长,我这里截图的时候没有等待,加载完成后也是可以直接查看的。
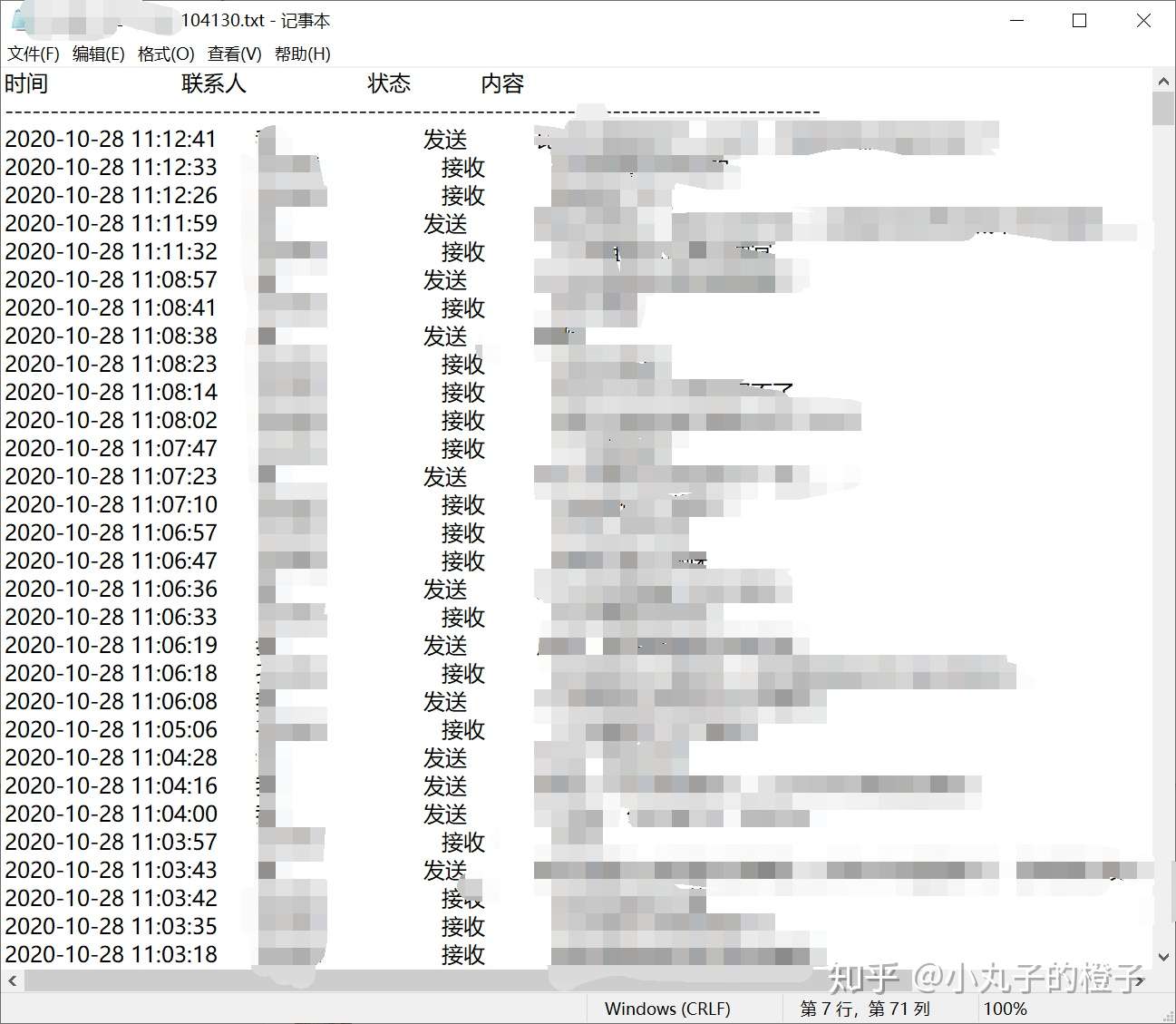
以下是内容:
在备份管理器中以专业模式查看并导出
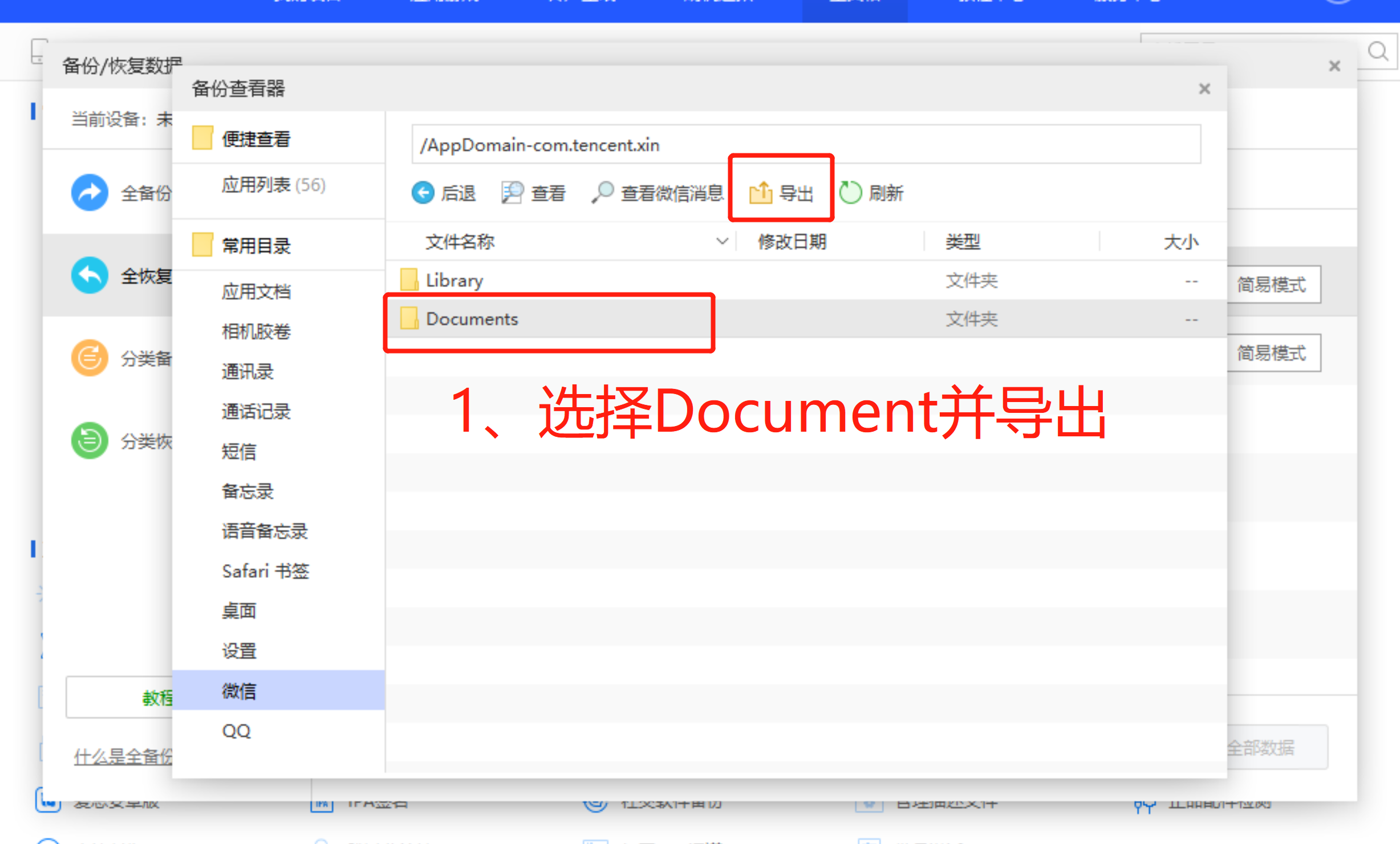
使用楼月助手导出
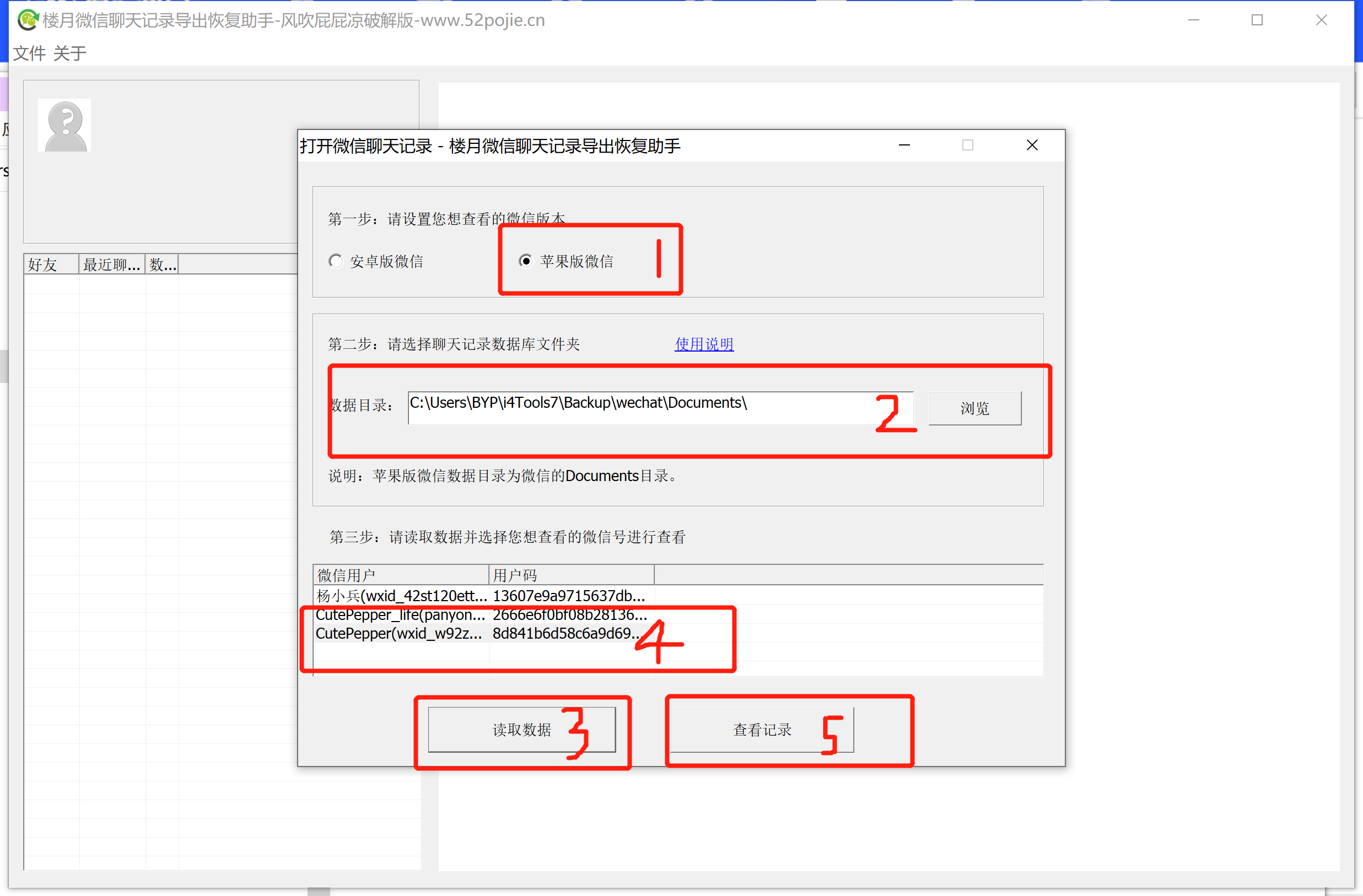
选择你与TA的文件夹,打开html,并转成TXT
如何生成词云图
事先准备
- 安装wordcloud库
- 安装Jieba库
处理聊天记录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66# -*- coding: utf-8 -*-
# @Time : 2020/10/31 10:35
# @Author : byp
# @File : processMessageTxt.py
import sys
import re
messageDir = "./data/messageDir/"
def processI4(input_filename):
fin = open(messageDir + input_filename, "r", encoding='utf8')
fout = open(messageDir + "__" + input_filename, "w", encoding='utf8')
nCol=0 #计数器--行数
for line in fin.readlines():
if line[0] == '-' and line[1] == '-' or nCol == 0:
nCol += 1
pass
else:
str = line[55:].lstrip()
fout.write(str)
nCol += 1
def processQQ(input_filename):
fin = open(messageDir + input_filename, "r", encoding='utf8')
fout = open(messageDir + "__" + input_filename, "w", encoding='utf8')
for line in fin.readlines():
if len(line) > 0:
if line[0] == '2' and line[1] == '0' or (line[:4] == "http") or (line == "[图片]"):
pass
else:
fout.write(line)
def processLouyue(input_filename):
fin = open(messageDir + input_filename, "r", encoding='utf8')
fout = open(messageDir + "__" + input_filename, "w", encoding='utf8')
# 通过空格来筛选
for line in fin.readlines():
if line[0] == " ":
a=line.lstrip()
# b=re.sub(u"[.*?]", "", a)
# 去除掉表情符号
b=re.sub('\\[.*?\\]','',a)
fout.write(b)
else:
pass
def test():
# txt = "_20201103_222047.txt"
# processWechat(txt)
txt="zyy.txt"
processLouyue(txt)
if __name__ == '__main__':
test()
if len(sys.argv) == 2:
processI4(sys.argv[1])
else:
print('[usage] <input>')生成词云图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90# -*- coding: utf-8 -*-
# @Time : 2020/10/31 10:49
# @Author : byp
# @File : wordCloud.py
import re
import collections # 词频统计
import sys
import numpy as np
import jieba # 结巴分词
import wordcloud # 词云展示
from PIL import Image
import matplotlib.pyplot as plt
import imageio
maskDir = "./data/maskDir/"
messageDir = "./data/messageDir/"
outputDir = "./data/outputDir/"
# 读取文件
def generateWC(preprocess_name, mask_name, output_name, font_path='C:/Windows/Fonts/msyh.ttc'):
f = open(messageDir+preprocess_name, encoding='utf-8')
string_data = f.read()
f.close()
# 文本预处理,删除聊天记录中的日期时间/换行缩进/特殊符号
pattern = re.compile(r'(\d+-\d+-\d+ \d+:\d+:\d+)|(\t|\n|\[|\]|\_)')
string_data = re.sub(pattern, '', string_data)
# 文本分词
word_list_exact = jieba.cut(string_data, cut_all = False) # 精确模式分词
object_list = []
# 自定义移除词库,包含各种ID/备注/常用助词副词/标点及空格/图片表情等
remove_words = [u'这个', u'…', u'那个', u'的', u',', u'和', u'是', u'对', u'@',u'他',u'但',u'她',u'觉得',
u'能', u'都', u'。', u' ', u'、', u'中', u'在', u'了', u'时候', u'今天',
u'要', u'人', u'找', u'这', u'还有', u'你', u'我', u'嗯', u'啊', u'先',
u'如果', u'我们', u'呢', u'嘛', u'吗', u'呀', u'你们', u'不过', u'咋',u'看',
u'啦', u'什么', u'嘞', u'不', u'哦', u'去', u'吧', u'这么', u'说', u'会',
u'个', u'知道', u'小妹', u':', u'=', u'~', u'很', u'有', u'哈', u'就',
u'还是', u'不会', u'现在', u'那', u'应该', u'也', u'表情', u'可以', u'上',
u'点', u'刚刚', u'图片', u'还', u'太', u'多', u'跟', u'然后', u'得', u'?',u'哈哈哈',u'一个',
u'?', u'没', u'们', u'!', u'/', u'\x14', u'看看', u'我看', u'你看', u'就是', u'不是', u'点击播放',u'查看',u'全文']
# 将不在移除词库中的词添加到object_list
for word in word_list_exact:
if word not in remove_words:
object_list.append(word)
# 词频统计
word_counts = collections.Counter(object_list)
#检查词频前10数据
word_counts_top10 = word_counts.most_common(10)
print(word_counts_top10)
# 生成词云
# mask = np.array(Image.open('yuanzehao.jfif')) #词云背景
mask = imageio.imread(maskDir+mask_name)
wc = wordcloud.WordCloud(
scale=32, #分辨率
font_path=font_path, #字体
mask=mask, #背景
max_words=350, #最大词数
max_font_size=250 #最大字体
)
wc.generate_from_frequencies(word_counts) #生成词云
# print("生成词云")
image_colors = wordcloud.ImageColorGenerator(mask)
# print("从背景图建立颜色方案")
wc.recolor(color_func=image_colors)
# print("#将词云颜色设置为背景图方案")
wc.to_file(outputDir+output_name)
print("已将词云保存至"+output_name)
def test():
input_name="__zyy.txt"
mask_name="pika.jpg"
output_name="zyy.png"
generateWC(input_name,mask_name,output_name)
if __name__ == '__main__':
test()
if len(sys.argv) == 5:
generateWC(sys.argv[1], sys.argv[2], sys.argv[3], sys.argv[4])
elif len(sys.argv) == 4:
generateWC(sys.argv[1], sys.argv[2], sys.argv[3])
else:
print('[usage] <input>')生成图片展示

注:后期可能会把代码打包成exe,目前没时间弄了呀
Conclusion
本文主要记录了如何把你手机里的一条条聊天记录生成一张张美妙的词云图,其实数据分析并不难,麻烦的是前期的数据准备工作,特别是对于IOS这种较为封闭式的系统。本文详细的介绍了如何从你的IOS手机中导出聊天记录,相对于其他方式,你不用担心自己的隐私会被泄露,且仅需要爱思助手这个较为常用的软件,较为方便。
下面谈一谈为什么会做这个东西?词云图我一直觉得是一个非常有趣、使用、浪漫的工具。首先从功能上说,它的可视化效果好,可以过滤无用的文本、渲染频率高的关键字,通过字体大小对比就能区分词频。在我们分析调性的时候,例如标题、内容、留言,“词云”能起到很好的辅助作用。其次从颜值上说,一张漂亮、一目了然的词云图,真的能吸引人的目光。
所以大概半年前我闲着没事干的时候就研究了一下,其实对于IOS来说最麻烦的是导出聊天记录,我最后尝试了较多的方法,发现I4这个是最简单、且不付费的。但是为什么我半年前完成的Project到了今天才写文档呢??我自己也不知道呢+_+。。。。。。

